Chegando no limite da tecnologia, e agora para aonde vou?
Nós de tecnologia em geral, somos early adopter (gostamos de abraçar novas tecnologias, mesmo sem saber ao certo porque ela existe), quando falamos em desenvolvimento não é muito diferente.
- Por que não usamos o banco de dados X?
- Podemos usar a linguagem de programação Y!
- O serviço Z resolve 100% dos nossos problemas!
Vamos assumir que as afirmações acima estejam 100% corretas (lançamos o primeiro erro), a solução irá servir para "vida toda" ou daqui a alguns meses tenham que olhar para ela, porque batemos em algum limite da implementação, arquitetura ou da própria tecnologia?
Se chegarmos em algum limite qual será os passos para correção? Dado que o software está em produção e não temos tempo hábil para pousar o avião?
Você já escutou pessoas com mais experiência dizendo: a teoria, na prática é outra
Quando estamos lendo texto onde fala:
- o Google usa
- o Facebook usa
Busque entender se essa tecnologia (ou solução) é para o momento atual da sua empresa e/ou software, ou está indo na onda de grandes players que tem estrutura totalmente diferente da sua?
O software, qual o problema à ser solucionado
Time, precisamos desenvolver uma API que irá solicitar consulta em diversas APIs (software de terceiros), pré processar (colocar os dados em nossa estrutura unificada), após processar salvar no Serviço de Store (serviço já existente)
Olhando a descrição acima e pensando em arquitetura de software, chego em uma arquitetura nesse caminho:
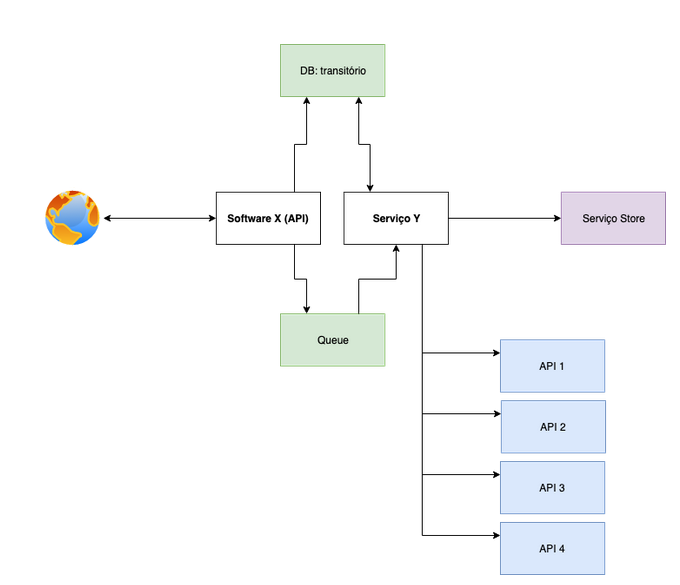
Software X (API): API interna onde recebemos solicitação para disparar consulta nas APIs de terceiros
Serviço Y: Consulta assíncrono todas as APIs de terceiro, coloca na estrutura que o Serviço Store precisa e envia para o Serviço Store
API 1, 2, 3, 4: APIs a ser consumida, cada API retorna de uma forma, JSON, XML, SOAP e etc
Serviço Store: Serviço já existente para armazenamento de dados
DB: transitório: Banco de dados que armazenamos o retorno de todas APIs (1, 2, 3, 4) antes do pré processamento, após ser processado pode ser deletado.
Queue: Bando de dados de fila
Dados transitórios
Escolher os componentes que iremos utilizar para compor uma solução não é um trabalho muito simples, principalmente quando olhamos para uma solução com pensamento macro e não o que ela pode se tornar no futuro.
Vamos colocar uma premissa para essa escolha: o time conhece e usa MongoDB em produção
Como o time usa MongoDB em produção vamos usar esse banco de dados para armazenar o retorno das APIs com a seguinte estrutura:
{
"headers": {},
"body": "", // retorno da API, nem sempre será JSON, pode ser XML e sera salvo como raw (string)
"status_code": 200 // http status code
}
Software em produção
O desenvolvimento do software foi relativamente tranquilo, foi usado soluções que o time possuía domínio e não gerou débito técnico.
Aproximadamente 1 ano depois a solução de monitoramento começou enviar alguns alerta reportando que não estava conseguindo salvar os dados no MongoDB, o documento estava com mais de 16mb, ou seja, chegamos no "limite" do banco de dados.
Ao olhar esses casos mais de perto, chegava um grande XML que passava do limite pré definido pelo MongoDB.
Se você está começando usar MongoDB não chegou até essa parte da documentação, vale a leitura para entender sobre os limites do MongoDB.
Após chegar nessa limitação pensamos em 4 possíveis soluções:
- Compressão no conteúdo, dado que é XML poderia tirar espaço e/ou alguns parâmetros que não usamos, mas estaria postergando o problema, no futuro poderia voltar ter o mesmo problema;
- Alterar a estrutura de registro salvando 1 registro para controlar outros N registro com documento feito split (dividindo a string);
- Alterar o limite do tamanho máximo da coleção;
- GridFS (recomendação do MongoDB, To store documents larger than the maximum size, MongoDB provides the GridFS API).
No primeiro momento a solução 3 me parecia ser ótima, bastava mudar o tamanho do limite máximo pré definido pelo MongoDB (para criação de novos documentos) e tudo funcionaria perfeitamente, olhando a documentação (alterar a opção nsSize) é extremamente simples, de fato a alteração no MongoDB é simples, porém o drive do MongoDB para Python seta os 16mb em variável interna para tratar documentos, alterar esse limite não é tão trivial, seria necessário fazer monkey patch ou um fork do drive, quando cheguei nesse momento foi o momento de tirar o pé do acelerador e pensar na próxima alternativa.
Para o próximo passo a solução 2 me parecia ser ótima, até ter que lidar com uma grande string e ter que colocar grandes funções para tratar tamanho de strings menores, isso que não cheguei no momento de ter um registro para controlar outros registros. Ao ver o começo da implementação a complexidade me fez abrir mão e passar para próxima opção.
As soluções listadas acima foi mais ou menos a ordem até chegar na solução 4.
Solução final
O software envia para o MongoDB para salvar como uma collection normal, quando recebemos o erro de documento muito grande, tratamos o erro criando um arquivo no GridFS com o conteúdo do XML e colocando a referência do arquivo criado na estrutura do documento, ficando da seguinte forma:
{
"headers": {},
"gridfs": ObjectID(""), // ID interno de referência do mongodb
"status_code": 200 // http status code
}
No software que lê esse documento fazemos uma condição if tratando se existe o nó gridfs:
obj = mongodb.find_one({...})
if obj.get('gridfs'):
fs = GridFS(...)
body = fs.get(obj['gridfs'])
obj['body'] = body.read()
obj.pop('gridfs')
return obj
Dessa forma retornamos a mesma estrutura independente de onde foi salvo o conteúdo (próprio documento ou GridFS), assim ficando agnóstico para o software lê os dados.
Nem tudo funciona tão bem como esperamos (não existe bala de prata), alguns pontos extremamente importantes para ter conhecimento:
- Leitura e escrita no GridFS é mais lenta que um documento;
- Estamos armazenando dados em outra coleção do MongoDB, ou seja, o processo de limpeza do banco de dados agora precisa olhar para outras coleções (como mencionado é um dado transitório, podemos apagar todos os dados a qualquer momento), usamos Expire Data via TTL do MongoDB.